Motivation
训练 RNN Language Model 时,大词表是系统瓶颈。
本文提出一种空间压缩方法,通过共享输入和输出的 embedding 层的结构参数来减少总参数,并能够保持原来的表示能力。
Methods
Random Parameter Sharing
Input Embedding Layer
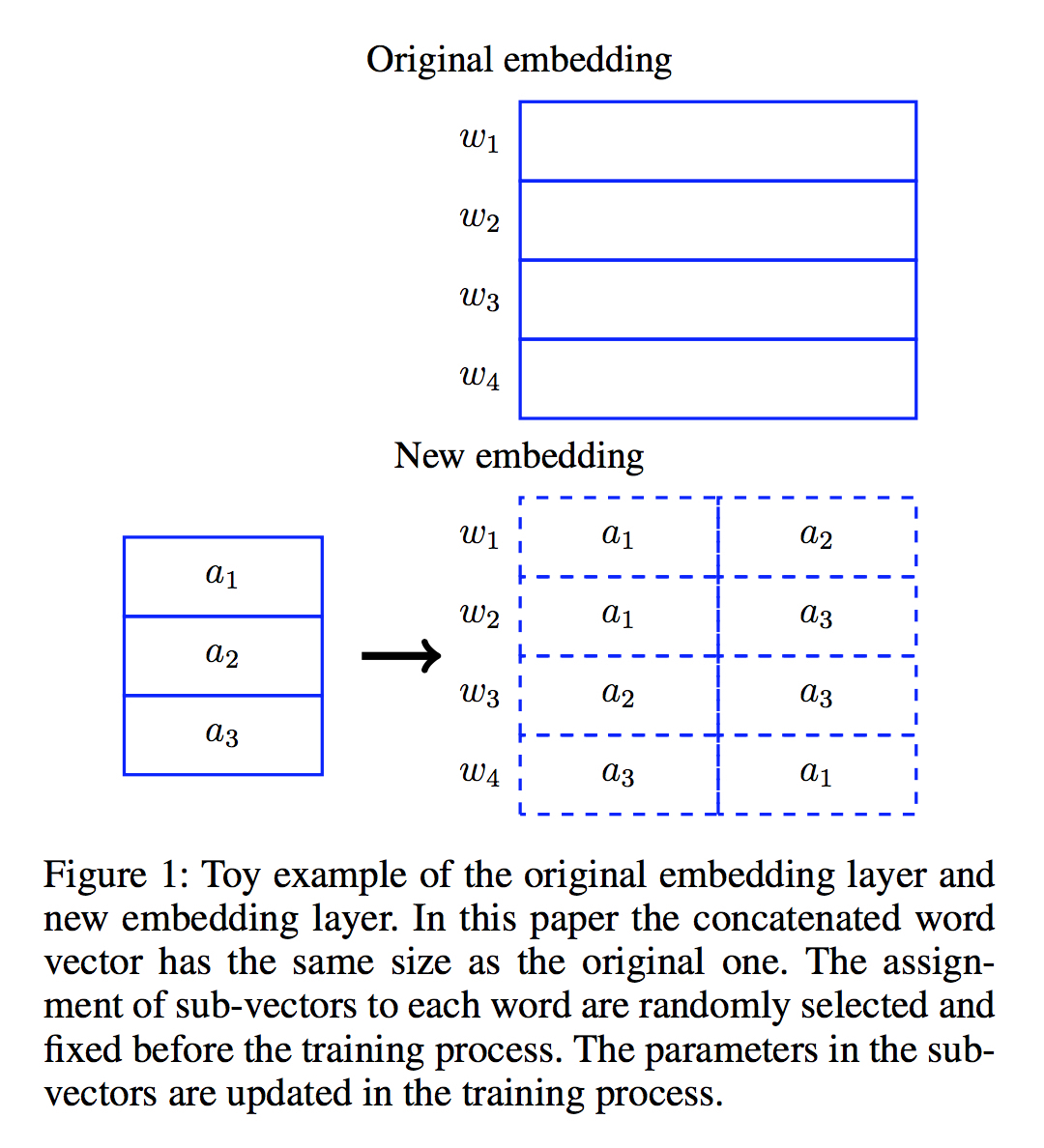
对大小为 $V$ 的词表,每一个词的 embedding (假设维度为 $N$ )被分成 $K$ 份,则共有 $V\times{K}$ 个 subvecs(维度为 $\frac{N}{K}$),通过随机算法将这 $V\times{K}$ 个subvecs 映射到总数为 $M$ 个互不相同的 subvecs 上,尽量保证每个 subvecs 使用次数相同。
这样下来,总的 Input Embedding 层参数从 $V\times{N}$ 减少为了 $M\times{\frac{N}{K}}$ 。如下图所示,共享版的 embedding 层参数只有原来的 3/8
Output Embedding Layer
同样的,可以将 target 端的 embedding $e_{w}$ 分成 $K$ 份 ,即 $e_{w} = [a_{w1}, a_{w2}, … a_{wk}]$ 则在计算 $z_{w} = h^{T}e_{w}$ 时,能够如下对问题进行重写:
其中 $h_{i}^{T}$ 为将 $h^{T}$ 均匀拆分为 $K$ 份后的一份,因此可以
- 先计算所有的 $h_{i}^{T}a_{wi}$,这一步的复杂度为 $O(\frac{MH}{K})$,其中 $M$ 为不相同的 subvecs 个数,$H$ 是隐层向量 $h^{T}$ 的维度。
- 计算所有的 $z_{w}$ , 这一步复杂度为 $O(VK)$
所以总的复杂度从 $O(VH)$ 减小到了 $O(\frac{MH}{K} + VK)$